来自DeepSeek的最新研究:DeepSeek-OCR,一种探索通过光学2D映射来压缩长上下文的新方法
LLM处理长文本的计算成本,又有了新的破解思路。把长长的上下文,直接渲染成一张图片,再喂给模型,这样做的好处是,原本数千上万个文本token,现在可能只需要几百个视觉token就能表示,实现了信息的高效压缩
实验结果相当惊人:
在压缩率小于10倍时(即文本token数是视觉token数的10倍以内),模型OCR解码准确率高达97%
即使在20倍的超高压缩率下,准确率依然能保持在60%左右
在主流的文档解析基准测试 OmniDocBench 上,DeepSeek-OCR 用更少的视觉token,实现了超越SOTA模型的性能
更重要的是,这项技术不仅是科研探索,还具备极高的实用价值。在生产环境中,单台A100-40G GPU每天就能处理超过20万页的文档,为大模型训练提供海量数据
目前,相关的代码和模型权重均已开源
https://github.com/deepseek-ai/DeepSeek-OCR/
https://huggingface.co/deepseek-ai/DeepSeek-OCR
什么是“上下文光学压缩”?
LLM在处理长文本时,面临的核心挑战是其固有的二次方计算复杂度。随着序列长度的增加,计算资源和时间会急剧增长。
DeepSeek研究人员提出了一个反直觉却又合乎逻辑的想法:利用视觉模态作为文本信息的压缩媒介
相比于一长串的数字文本token,一张包含同样内容的文档图像,可以用远少于前者的视觉token来表示。这就好比将一本书的内容拍成一张照片,这张照片本身就包含了所有的文字和排版信息
这种“文本→图像→视觉token”的转换过程,就是所谓的上下文光学压缩(Contexts Optical Compression)
为了验证这一想法,团队构建了DeepSeek-OCR模型。从图(a)的压缩实验中可以看出,视觉token数量和OCR解码精度之间的权衡关系:

64个视觉token(左侧柱状图):当文本token数在600-700之间(压缩率约10.5倍)时,精度为96.5%。随着文本量增加到1200-1300(压缩率接近20倍),精度下降到59.1%
100个视觉token(右侧柱状图):在600-700文本token(压缩率6.7倍)时,精度高达98.5%。即使文本量增加,压缩率达到12.6倍时,精度仍有87.1%
这意味着,在10倍压缩的范围内,模型几乎可以“无损”地从图像中解码出原文
DeepSeek-OCR是如何实现的?
DeepSeek-OCR的架构由两部分组成:一个核心的编码器DeepEncoder,和一个解码器DeepSeek3B-MoE-A570M

解码器采用了高效的MoE(Mixture-of-Experts)架构,而整个系统的创新关键在于DeepEncoder
为了在处理高分辨率图像时,依然能保持较低的计算激活和可控的视觉token数量,DeepEncoder的架构设计非常巧妙,它串联了三个关键组件:
1.SAM-base (ViTDet):利用窗口注意力(window attention)机制处理局部感知,将输入图像(如1024x1024)分割成大量patch(如4096个)。由于是窗口注意力且模型规模不大(80M),激活值是可控的
2.16倍卷积压缩器:在特征进入全局注意力模块前,通过一个2层卷积网络进行16倍的下采样,将视觉token数量从4096个锐减到256个
3.CLIP-large (ViT):利用密集的全局注意力(dense global attention)机制提取视觉知识。由于输入的token数量已经大幅减少,这里的计算开销也变得可以接受
这种“先局部处理,再压缩,后全局理解”的串行设计,使得DeepEncoder能够在处理高清图像的同时,生成数量极少的视觉token,实现了内存和token的双重压缩
效果炸裂,token用得还少
权威的文档理解基准 OmniDocBench 上,DeepSeek-OCR展现了其卓越的实用性能。
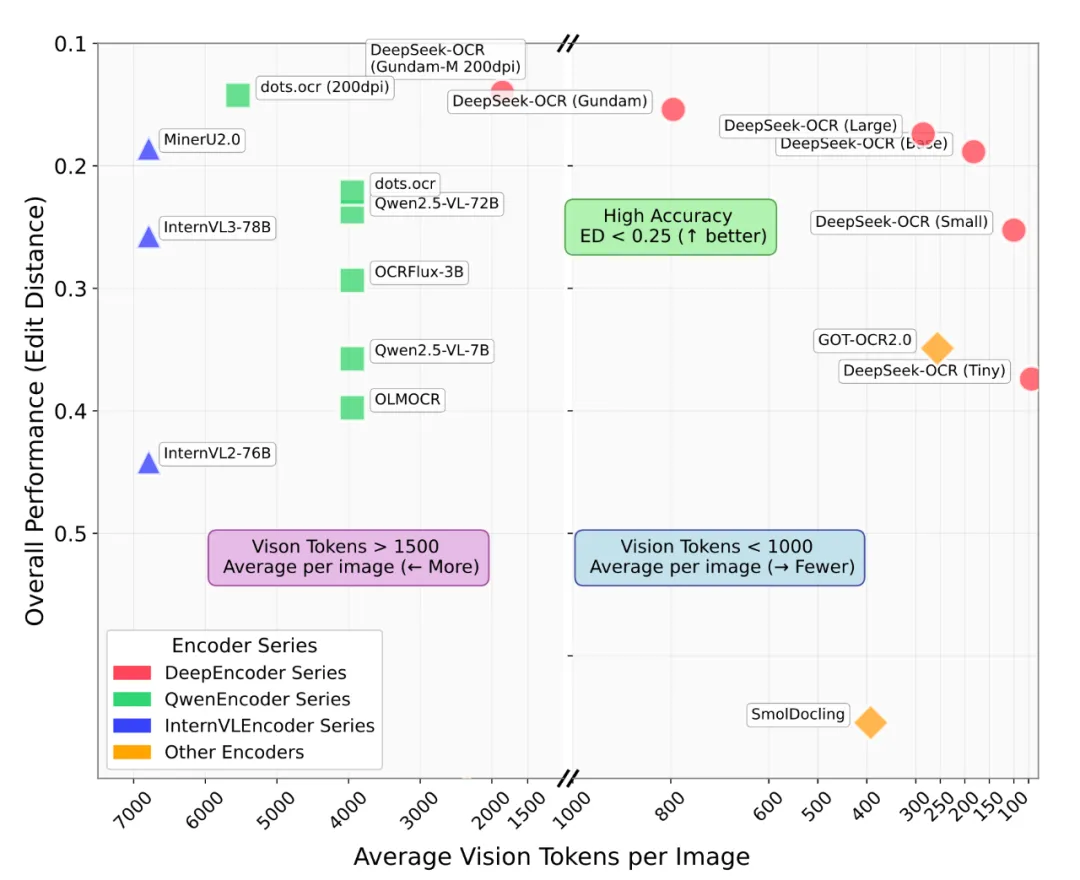
从上图的性能对比中可以看出,DeepSeek-OCR(红色圆点)在“平均每张图的视觉token数”(横轴)上处于最右侧区域,意味着它使用的token数量最少。而在“整体性能(编辑距离)”(纵轴,越低越好)上,它却达到了SOTA水平
具体来看:
仅用100个视觉token(Small模式),就超越了使用256个token的 GOT-OCR2.0
使用不到800个视觉token(Gundam模式),性能就超过了需要 6000+ token的 MinerU2.0
这充分证明,DeepSeek-OCR在实际应用中非常强大,并且由于其极高的token压缩率,为未来的研究留下了更高的想象空间
不止于OCR的“深度解析”
除了常规的OCR能力,DeepSeek-OCR还具备对文档内图像进行深度解析的能力
无论是金融研报里的图表:

还是化学文献里的分子式:

甚至是数学题中的几何图形,它都能进行结构化的解析和转换
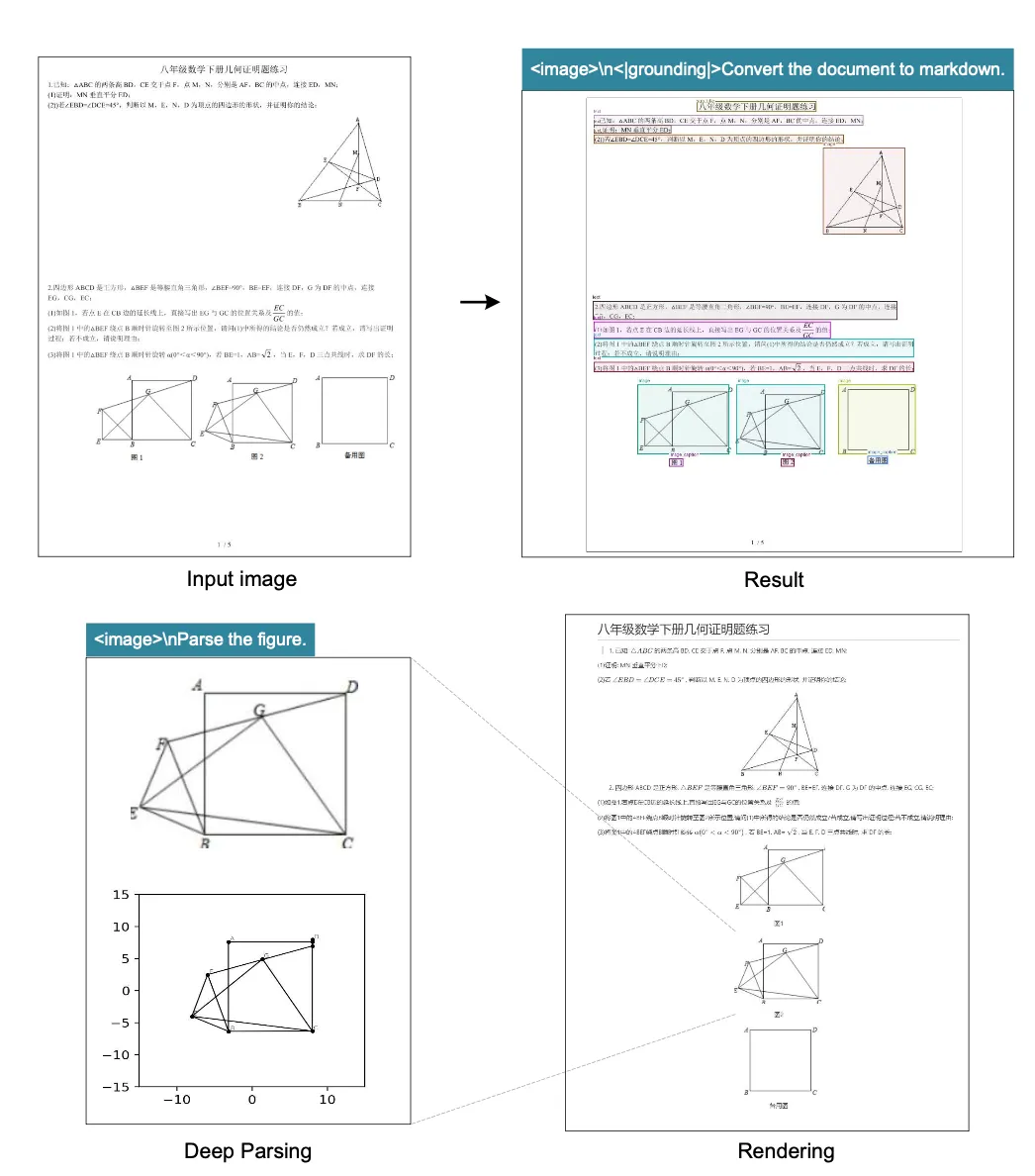
此外,得益于其多语言的训练数据,模型还能处理包括阿拉伯语、僧伽罗语在内的近百种语言的文档
未来构想:模拟人类记忆遗忘
这项研究最引人遐想的部分,是它为实现LLM的记忆遗忘机制提供了一种可能的路径
研究人员将上下文光学压缩与人类记忆的衰退过程进行了类比:
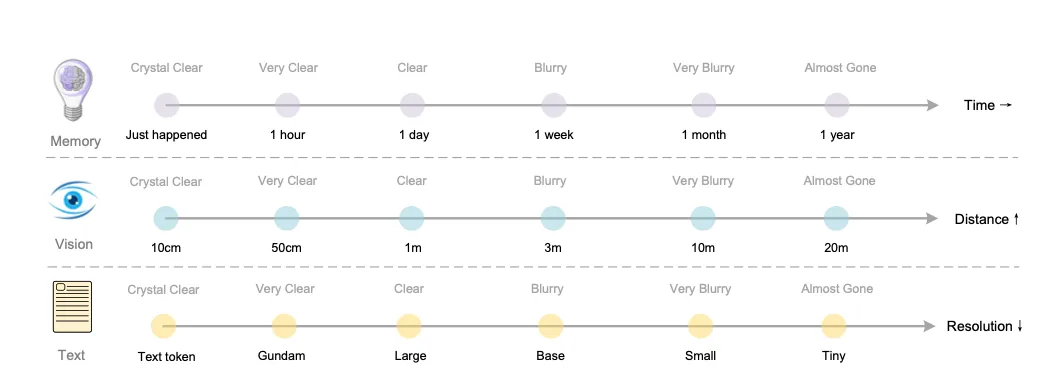
近期记忆 (Recent Contexts):就像近处的物体,清晰可见。可以将其渲染成高分辨率图像,用较多的视觉token来保留高保真信息
远期记忆 (Older Contexts):就像远处的物体,逐渐模糊。可以将其渐进式地缩放成更小、更模糊的图像,用更少的视觉token来表示,从而实现信息的自然遗忘和压缩
通过这种方式,模型可以在处理超长对话或文档时,动态地为不同时期的上下文分配不同数量的计算资源,从而可能构建出一种理论上无限长上下文的架构。
总而言之,DeepSeek-OCR不仅验证了“上下文光学压缩”这一新颖想法的可行性,还提供了一个性能强大、极具实用价值的开源模型,为解决LLM的长上下文难题开辟了一个全新的、充满希望的方向。
论文地址:
http://github.com/deepseek-ai/DeepSeek-OCR
本文由公众号“AI寒武纪”授权转载| https://mp.weixin.qq.com/s/vS9doopxozGKnuhFSZJGpg|(编辑:潇飞)