最近,DeepSeek又发布了最新的开源模型DeepSeek-OCR。
在海内外火的一塌糊涂的同时,也引发了包括Andrej Karpathy在内一众大神对大模型输出端未来要走向何方,以及传统分词器的激烈吐槽。

(一句话翻译:应该用图像做LLM输入,传统文本分词器迟早要完)
看名字,很容易将DeepSeek-OCR当成一个做pdf解析的模型。当然,DeepSeek-OCR也的确能这么做,但是更重要的是,针对现在行业内最困扰的LLM长上下文输入带来的成本飙升、效果雪崩,DeepSeek-OCR给出了新解法。
简单来说,用视觉模态作为长上下文的压缩载体,DeepSeek-OCR在保证精度的同时,可以实现模型算力与效率的突破。
一定程度上,它的出现,救了大模型的长文本处理,也给受困于成本、准确性的RAG,带来了新解法。
接下来,我们将重点解读DeepSeek-OCR的技术细节、落地思路,以及它对RAG的启示。
Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR
GitHub:https://github.com/deepseek-ai/DeepSeek-OCR
01 核心矛盾:传统长文本处理走到死胡同
理解DeepSeek-OCR的突破性之前,我们需要先了解一个背景知识:长上下文输入对LLM的输出成本与输出质量都带来了极大挑战,而传统方案围绕长上下文做文本 token 优化的思路已见顶。
具体来说,现有 LLM 处理长文本时,计算量会随 token 序列长度呈O (n²) 二次增长。这意味着当文本 token 从 1000 增至 10000 时增长十倍,自注意力计算量会扩大 100 倍,直接导致即使最高端的 GPU 也面临内存溢出或推理超时的问题。
更关键的是,当 token 数量过多时,大模型的注意力权重会趋于均匀分布,或者聚焦开头结尾,导致模型无法聚焦关键信息,从而影响输出质量。
同时,在处理一些多模态文档比如pdf论文或者ppt的时候,文本 token 化方案也存在天然局限:
- 无法保留文档布局、图表、公式等非文本信息,学术论文、金融财报中的数据趋势、格式逻辑会丢失;
- 多语言场景下需维护多套分词器,中文、阿拉伯语等不同语系的处理逻辑不通用;
- 压缩比有限,传统分词器仅能实现 1-2 倍 token压缩,无法满足超长文本(如万级 token)的高效处理需求。
02 DeepSeek-OCR :光学压缩搞定长上下文
DeepSeek-OCR 的核心突破是提出Contexts Optical Compression(上下文光学压缩) 范式,通过文本 - 图像 - 视觉 token的转换,解决长文本处理的效率与信息完整性问题。其核心流程分三步:
第一步,将长文本渲染为结构化文档图像,完整保留文字、图表、公式及布局信息;
第二步,通过视觉编码器将图像压缩为少量视觉 token,实现 7-20 倍 token 缩减(OmniDocBench 测试中最高达 60 倍);
第三步,语言解码器将视觉 token 还原为文本,同时保持 97% 以上的识别准确率。

(上图为不同模型的识别准确率对比)
这一范式的关键在于:文档图像可通过更少的视觉 token 承载与文本等量的信息,且天然兼容非文本元素,从根本上规避了文本 token 化的缺陷。
技术上来看,DeepSeek-OCR 采用了编码器DeepEncoder + MoE 解码器的架构。

其中,编码器DeepEncoder是整个系统的突破点。它承担了图像特征提取与视觉 token 压缩的双重任务,结构上是三段式设计:
SAM-base(800M 参数):采用窗口注意力机制处理高分辨率图像,在控制激活内存的同时,精准捕捉文字、标点等局部细节;
16× 卷积压缩器(2 层):将图像 token 数量大幅缩减,例如 1024×1024 图像可从 4096token 压至 256token,实现 16 倍压缩;
CLIP-large(3 亿参数):通过密集全局注意力提取图像全局语义,确保压缩后不丢失文档逻辑(如表格行列关系、公式结构)。
此外,DeepEncoder 支持 Tiny、Small、Base、Large、Gundam、Gundam-M 6 种分辨率模式,可根据任务需求选择 64-1853 个不等的视觉 token,兼顾处理精度与资源消耗。(用于大模型上下文处理时,我们可以选择将古早、非核心内容用低分辨率压缩,近期重要内容用高分辨率压缩)

DeepEncoder 解决了压缩问题之后,MoE 解码器是高效文本还原的关键。DeepSeek-OCR 选用的是DeepSeek3B-MoE-A570M作为解码器。
其核心优势在于参数效率:仅激活 570M 参数(64 个专家中选 6 个 + 2 个共享专家),在 3B 模型体量下实现接近大模型的处理精度;并支持视觉 token→文本 token的非线性映射,可将图表还原为 HTML 表格、化学公式转换为 SMILES 格式,实现结构化输出。
从性能指标看,该解码器在纯文本数据上单 A100-40G 即可支撑每秒 2500token 的高吞吐量生成,极大降低了部署门槛。
03 DeepSeek-OCR的意义
DeepSeek-OCR 的意义并非单纯提升 OCR 精度(事实上,在网友的测试中,针对一些手写、专业场景中,DeepSeek-OCR 也没有达到sota)。
它的意义其实是通过跨模态压缩,为后续长上下文 LLM、多模态、多语言文档理解模型提供了新的技术基座。
行业痛点一:图文混合文档的端到端处理
传统方案处理含图表、公式的文档时,需先通过独立 OCR 将图像转文本(易丢失格式、引入误差),再用分词器处理文本。而 DeepSeek-OCR 直接将图文混合内容转为统一视觉 token,无需中间转换环节,完整保留文档结构信息。
例如处理含折线图的财报时,视觉 token 可保留数据趋势,解码器能直接输出可编辑的 HTML 表格,避免传统方案仅能提取图下文字说明的局限。

行业痛点二:多语言处理的通用性提升
传统分词器需针对不同语言单独训练(如中文需处理汉字组合,英文需处理字母序列),多语言场景下的模型维护成本极高。DeepSeek-OCR以图像为中间媒介,无需区分语系即可处理 100 种语言,大幅降低多语言文档的处理门槛。
行业痛点三:长文档处理的成本问题
传统长文本方案(如滑动窗口、稀疏注意力)均围绕文本 token 做裁剪或效率优化,本质是在 O (n²) 复杂度内做减法;而 DeepSeek-OCR 通过 文本→图像→视觉 token的转换,直接将计算基础从文本 token 转为视觉 token,相当于用更低复杂度的载体重构问题。
这种范式转变还带来了额外优势:可模拟上下文重要性的动态调整 —— 对近期内容用高分辨率生成多视觉 token(保留细节),对远期内容用低分辨率生成少视觉 token(节约资源),适配多轮对话、长程文档分析等场景的记忆需求。
04 展望
其实 DeepSeek-OCR 这东西,对 RAG 下一步发展,启发还挺大的。
DeepSeek-OCR 生成视觉 token的压缩思路,和文本用 Sentence-BERT 这类模型转成 Embedding 的操作,本质是一回事。都是靠把信息的维度变多,来实现信息的绝对数量变少。
更进一步来看,如果是针对图表等信息,DeepSeek-OCR 可以直接跳过解码器部分,将压缩内容直接提供给多模态大模型,进行内容的生成。
而未来的RAG,也有望从embedding相似性对比-还原原始文本片段-原始片段投喂 LLM 升级为检索 Embedding 向量-直供 LLM。
原因在于,当前传统RAG会反复重复分词→Embedding 生成的流程,存在不可忽视的效率浪费与信息损耗。
此外,传统RAG中,如果我们检索到的的是多个长文本片段,计算量会达到token 总量的平方,算力消耗不容忽视。
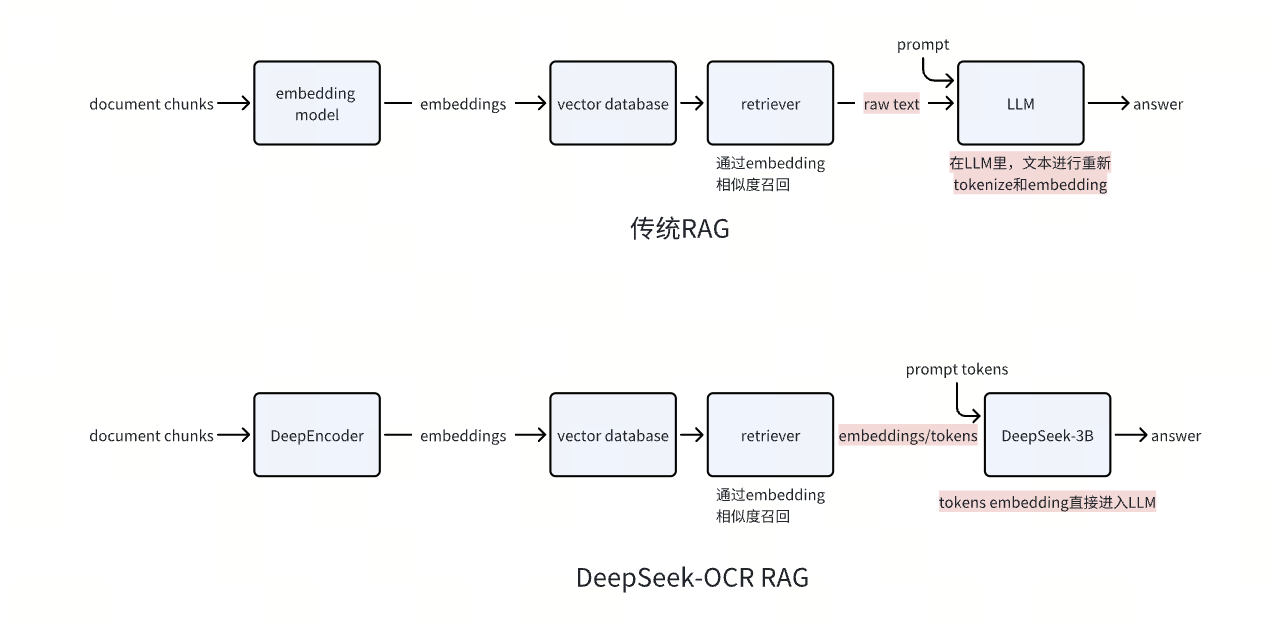
但如果选择检索 Embedding 直供 LLM,一方面,它无需经过传统 tokenize 的转换损耗。
更重要的是,在计算效率层面,会将在线处理复杂度大幅降低。通过离线预生成 Embedding + 在线向量检索的解耦设计,文档库的 Embedding 可一次性批量生成并存入 Milvus 等向量数据库,在线阶段仅需检索Top-K 个向量(通常不超过 20 个)替代原始文本即可满足需求。
不久前,Meta 发布的 REFRAG 架构即是类似逻辑。详情参考Meta如何给RAG做Context Engineering,让模型上下文增加16倍
本文由公众号“Zilliz”授权AI产品之家转载,原文连接: https://mp.weixin.qq.com/s/We8GNJTQKluEF-xtI1_iJA