这是我最近在github上发掘的最有价值的一个AI开源项目:舆情智能体。 强烈建议大家去使用下这个工具

一句话概括:它能根据用户输入热点事件生成一份完整的舆情整理报告
第一眼看到项目的宣传图片,我隐隐感觉他们是在装逼,舆情收集需要海浪数据收集,三板斧就搞定?

周末本地部署并使用了下,才发现,人家压根没装逼,我真的挖到了一个宝藏开源
这篇文章有点长,但值得大家耐心看完。文章末尾我会附上本地部署的教程。
测试采用的热点事件是:小米汽车成都高速车祸
报告总共有27页
01专业的用户画像
通过多个社交主流平台(微博,抖音,小红书,知乎,快手)获取了民意数据,并且有详细的数据汇总和百分比。并且把用户群体分成了多个维度进行归类,统计。
对这些群体进行了详细的用户画像以及情感分析

这还没完,在数据画像和身份属性上挖掘得非常深入。还有各个不同身份属性的民意数据画像以及情感温度。
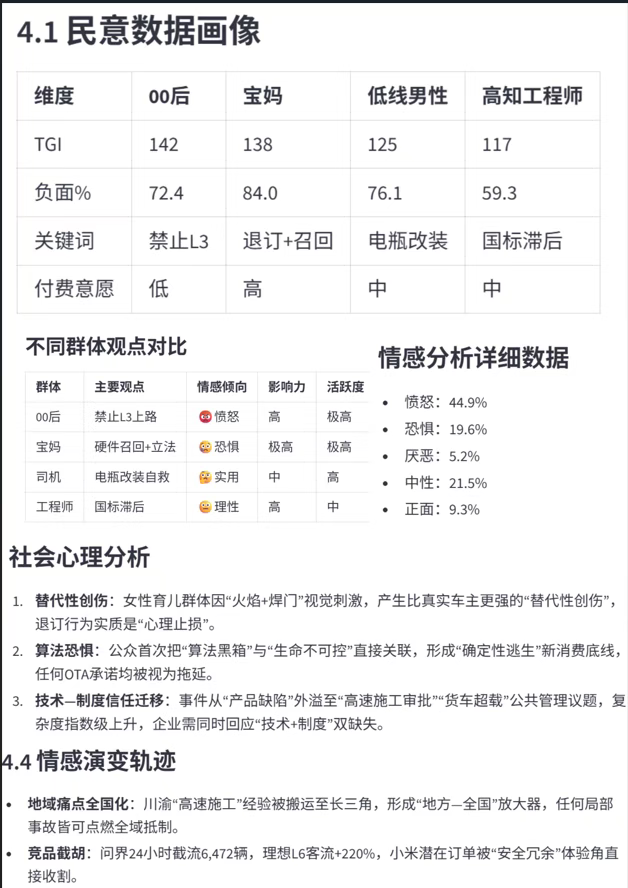
不同群体分析观点,社会心理分析以及情感演变轨迹全都包含在内。
我只截取了比较突出的部分,报告中其实还有更多的解读。
看到这的时候,我只能说:专业,真TM的专业。
02主流平台画像
用户画像结束,接下来就是平台画像。
首先是统计了该热点话题,各个平台的分布量。小米这个事件,热度最高的就是抖音和快手,占比超过6成
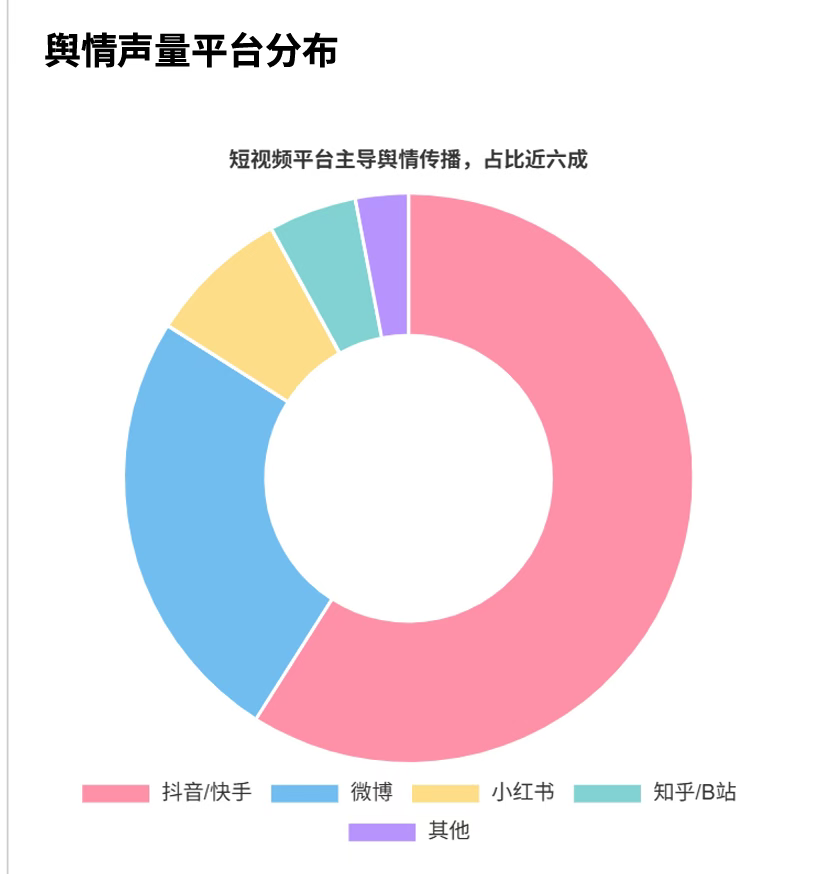
各个平台传播的特征以及核心内容,吸引用户的行为都有详尽的统计

甚至连平台的热点内容特点都能分析出来
是⼀个被媒体分析引擎精准定义为“杏仁核⾼频刺激模板”的15秒短视频

看到这里,你们知道我被震惊的是啥么,不是它的分析能力,而是它的数据获取能力
这绝不是靠爬取各大网页能得到的数据,而是对平台的内容,用户评论进行了精准爬取。这才是最恐怖的地方
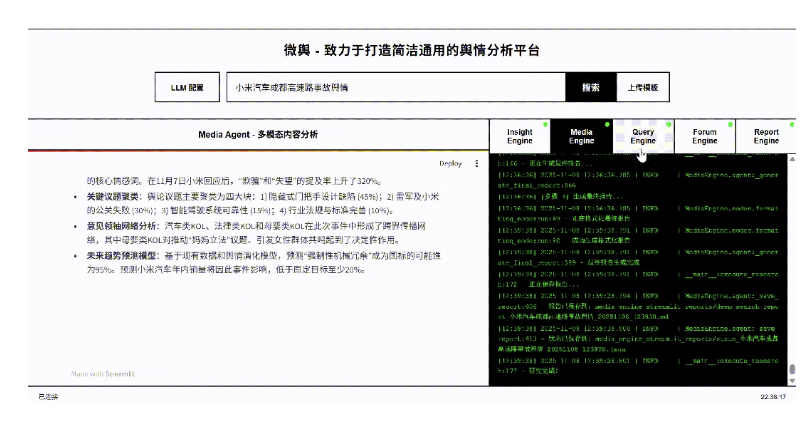
03多智能体协同系统
舆情智能体为啥这么牛逼,来看它的软件架构

如上图所示,它包含4个智能体
insight Agent: 也可以认为是调度智能体。它通过微博、知乎等社交媒体的爬虫抓取的原始数据,经清洗后存储到数据库,供Insight Agent深度挖掘, 接收Media Agent的多模态分析结果(如短视频中的热门标签、图片中的情感符号
- Query Agent:利用Tavily网络广度搜索。精准信息搜索:具备国内外网页搜索能力的AI代理
- Media Agent: 利用博查搜索进行深度搜索,多模态内容分析:具备强大多模态能力的AI代理
- Report Agent: 汇总所有的数据,形成报告
除了Report Agent,其他三个智能体都是并行工作。并相互交互数据
一次完整的数据分析包含下面表格的步骤

三个智能体采取又统一,有独立的工作方式。每个智能体都有自己的决策系统,反思系统。
任务分配完后,每个智能体独立完成任务,然后用论坛协作,也就是开会机制,在主持人agent的调度下,各个智能体分别发言汇报自己的工作成果
主持人生成总结,各Agent根据讨论调整研究方向,不断的进行迭代这一过程
跟我们人类的团队办公模式完全一模一样!
04部署以及使用方法
终于到了最关键的步骤:本地部署以及使用方法
项目地址;
https://github.com/666ghj/BettaFish
拉取代码后,把项目文件下的.env.example单独复制一份,命令为.env文件
首先要进行配置文件的配置。配置文件包含3个部分:数据库/大模型API/搜索API
一 :数据库配置

二 :大模型配置
根据作者的规划,每个智能体都配置了大模型,且还不能用同样的大模型,每个智能体采用的大模型在配置文件中都有推荐。

为了不让大家去各个大模型平台一一去获取API,作者推荐了一个平台:推理时代。
一个API秘钥,可以对接无限个模型
网址:https://aihubmix.com/
大家去注册后生成秘钥,同时也需要充值
API调用的baseURL:https://aihubmix.com/v1
可以参考我的这个配置。模型名称从推理时代上获取

三 搜索配置
搜索分别用到Tavily和博查。其中Tavily是免费使用,博查需要充值

注册申请的地址参考配置文件中给的地址
配置完后,就开始本地部署
项目提供docker安装和源码安装。这里就不建议用源码安装了,很麻烦。推荐用docker安装
拉取代码后一条命令就可以安装
docker compose up -d
整个项目有点大,超过5个G
部署完成后,网页端能打开就表明部署成功
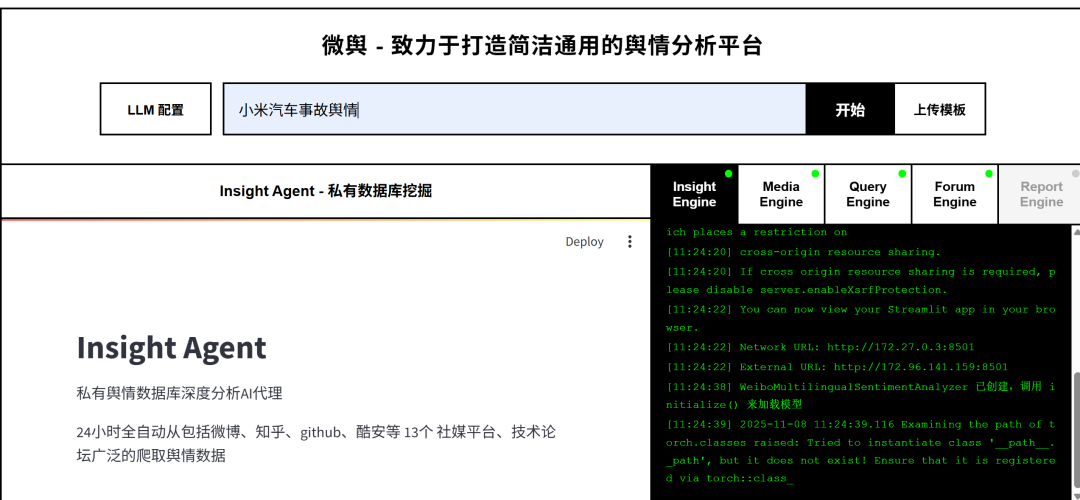
注意这里点开LLM配置看看,配置是否都同步。如果没同步,则需要把.env中的配置再手动填一次

点击保存并启动系统,就可以正常使用了。
使用成本如何
最后,来看看这次报告生成,花费了多少米
推理时代上消费4.3美刀的大模型调用,也有30块了。token消耗了1.1M,有点生猛

博查比较便宜,只消费了1.32元。

30多块,生成这样一个报告,不算便宜,但从报告质量角度来说,也不算贵。
好了,大家也去本地部署玩起来吧,有问题可以交流哦
本文由公众号“程序员猿AI”授权转载| https://mp.weixin.qq.com/s/7dVLtKBCTx1Jlaa2mHVb9g |(编辑:ZN)

⬆ 扫码加入AI产品交流社群,你有机会得到:
- 最值得关注的AI产品;
- 最新鲜的 AI 产品资讯;最实用的AI产品使用经验;
- 还有不定期赠送热门新品的邀请码、会员码。