一、人工智能背景介绍

1950年,“计算机之父”和“人工智能之父”艾伦·图灵(Alan M. Turing) 发表了论文《计算机器与智能》 ,这篇论文被誉 为人工智能科学的开山之作。 在论文的开篇 , 图灵提出了一个引人深思的问题: 机器能思考吗? 这个问题激发了人们无尽的想象 ,同时也奠定了人工智能的基本概念和雏形。
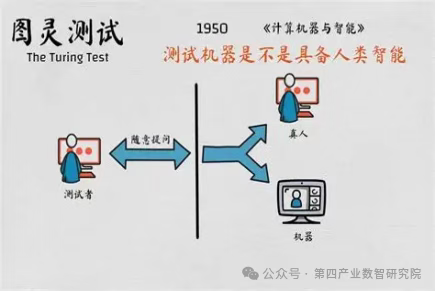
在这篇论文中 ,图灵提出了鉴别机器是否具有智能的方法,这就是人工智能领域著名的“图灵测试”。 如图所示 ,其基本思想是测试者在
与被测试者(一个人和一台机器)隔离的情况下 ,通过一些装置(如键盘)向被测试者随意提问。进行多次测试后 ,如果被测试者机器让平均每个测试者做出超过30%的误判 ,那么这台机器就通过了测试 ,并被认为具有人类智能。
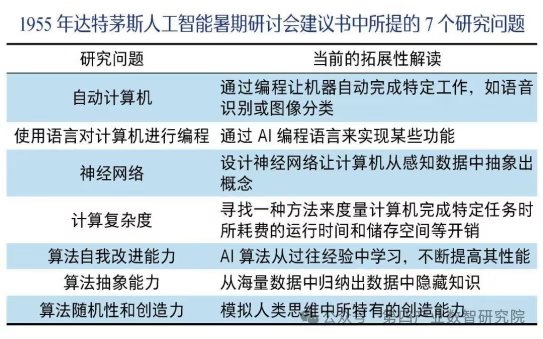
萌芽:1956年夏天,一场在美国达特茅斯(Dartmouth)大学召开的学术会议,多年以后被认定为全球人工智能研究的起点。2016年初,AlphaGo 与世界顶级围棋选手李世石的人机世纪之战,推动人工智能新浪潮 。
节点:2016年初,IBM在全球大举推出基于IBM Watson的认知计算,Watson的前身是1997年打败国际象棋大师卡斯帕罗夫的 “深蓝”。
未来:在前60年中,人工智能取得了阶段性成果,特别是在自然语言理解、语音识别、图像识别等领域,已经到了实际应用阶段。未来60年会改变生活方式。
二、大模型发展脉络
何为大模型?
大模型并非仅由参数量大来定义,更重要的是它遵循规模定律(Scaling Law):通过增加模型参数、数据集和计算资源,模型性能将获得持续的、可预测的提升。
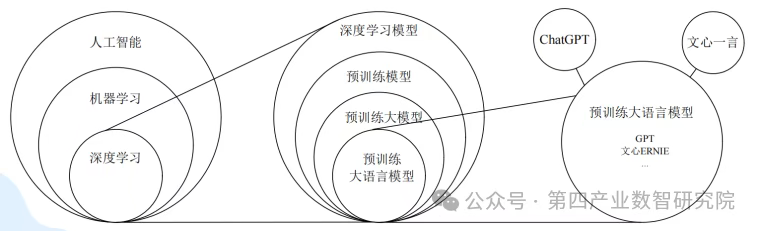
ScalingLaw本质上是对数据中蕴含的知识的描述,其核心理念是“生成即压缩,压缩即模型通过压缩大量数据,将数据智能的知识嵌入模型参数”。随着数据集中蕴含知识越来越多,所需要掌握知识的模型尺越来越大,模型智能性随之提升。大模型智能性主要源于数据。
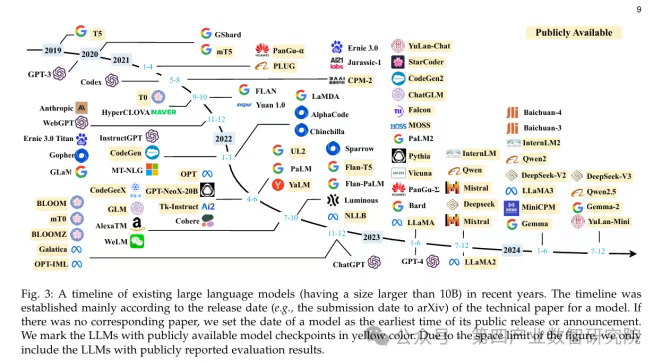
1.0 奠基期(~2022年)
GPT-3 诞生 = 人类登月时刻 → 证明“规模=智能”,但成本高昂,仅限少数巨头
2.0 规模引爆期(2023年)
ChatGPT 推出 → 大模型首次进入数亿用户 → 引发全球“参数竞赛”
瓶颈:上下文长度有限 & 推理成本高
3.0 效率与多模态革命期(2024-2025年)
竞争焦点转向更好用、更便宜、更多能
效率革命:量化 & 知识蒸馏 → 小模型也强大
长上下文:从几页纸 → 一本小说(128K窗口)
多模态融合:图像、语音、视频实时交互(GPT-4o)
AI Agent:从聊天机器人 → “数字员工”
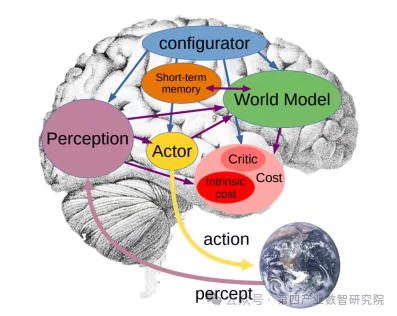
什么是世界模型?
1. 通过整合多模态数据(视觉、语言、传感器等)构建环境的动态认知。
其核心功能包括:
- 状态表征:理解当前环境状态(如物体位置、物理属性)
- 转移模型:预测状态变化规律(如物体运动轨迹)
- 反事实推理:推测未发生事件的结果
其他定义:输入是任何形式——输出为任何形式的模型。
2. 与LLM的区别:
- 世界模型强调对物理规律(重力、碰撞)和时空动态的建模,而非单纯语言关联
- 具备持续学习能力,可适应新场景
- 支持复杂决策规划(如自动驾驶避障)
三、大模型原理分析

Scaling Law:在大型语言模型(LLM)和其他深度学习模型中观察到的一种经验性规律,即模型的性能会随着模型规模(参数量)、训练数据量和计算量(算力)的幂律式增长而可预测地提升。
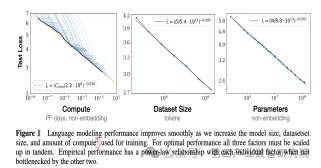
模型规模: 神经网络的参数量。通常越大越好。模型参数量(千亿→万亿)
训练数据量: 用于训练模型的文本/代码等数据的量。通常越多越好。(TB级→PB级)
计算量: 训练模型所需的浮点运算量。通常越多(训练时间越长/算力越强)越好。(千卡→万卡集群)
涌现能力:当大模型的规模(参数量、数据量、算力)增长到某个临界点(阈值)时,模型突然表现出一些在较小规模模型上不存在、难以预测、且无法通过简单外推较小模型行为来解释的新能力或行为。这些能力看起来像是“突然出现”的。
四、大模型发展思考:模型
| 能力 | 代表场景 | 价值 |
| 思维链推理 | 解数学题展示推理步骤 | 解决复杂逻辑问题 |
| 深度语义理解 | 理解文学作品中的隐喻,与思想 | 人机交互自然化 |
| 创造性生成 | 写小说/诗歌/商业方案 | 超越模板化的原创输出 |
模型更加通用,更加智能
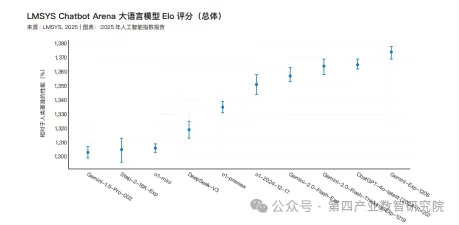
在 MMLU 测试中达到 GPT-3.5 水平(64.8 分)的模型,其推理成本从 2022 年 11 月的每百万词元 20 美元降至 2024 年 10 月的 0.07 美元(Gemini-1.5-Flash-8B),约 1.5 年内下降超 280 倍。
Epoch AI 估计,根据任务不同,大语言模型的推理成本正以每年 9 至 900 倍的速度下降。

悬而未解的问题:大模型为什么会有幻觉?
从训练方式上看:利用无监督学习技术,使模型能够根据上下文预测下一个词(数据之间的相关关系)。大模型的核心是基于自回归语言建模或填充式语言建模。
它的目标是:在已有上下文的基础上预测下一个 token(自回归模型,如 GPT)基于部分已知文本填充缺失的部分(填充式模型,如 BERT)无论是哪种方式,本质上模型都是在统计学习的框架下,根据训练数据中的概率分布来预测输出。因此,它并不具备真正的理解力,而只是生成在语义上高度符合统计规律的文本。
语言模型并不会验证“事实”,只会生成最可能的文本,模型学习的是数据中的相关关系,而非因果推理关系。
架构缺陷:基于前一个token预测下一个token,这种单向建模阻碍了模型捕获复杂的上下文关系的能力;自注意力模块存在缺陷,随着token长度增加,不同位置的注意力被稀释。
信念错位:基于RLHF等的微调,使大模型的输出更符合人类偏好,但有时模型会倾向于迎合人类偏好,从而牺牲信息真实性。
数据缺陷:数据中捕获的事实知识的利用率较低。数据缺陷分为错误信息和偏见(重复偏见、社会偏见),此外大模型也有知识边界,所以存在领域知识缺陷和过时的事实知识。
大模型真的会思考吗?

更像是以相关的模式去逼近因果推理的方式
复杂推理仍是人工智能面对的难题
尽管通过思维链(Chain-of-Thought)等推理机制的引入显著提升了大语言模型的性能,这些系统仍无法可靠解决本可通过逻辑推理获得确定性答案的问题——包括数学运算和任务规划等,尤其当问题规模超出其训练范 围时。这一缺陷严重影响了人工智能系统的可信度,使其难以胜任高风险场景的应用需求。
大模型发展思考:数据层面
人工智能系统在算法上取得实质性改进的主要驱动力之一,是在越来越大的数据集上扩展模型及其训练。然而,随着互联网训练数据的日益枯竭,人们越来越担心这种扩展方法的可持续性以及数据瓶颈的可能性,因为在这种情况下,规模收益会逐渐减少。
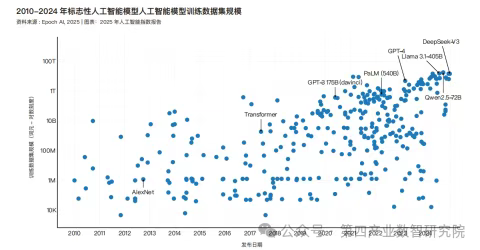
数据会有枯竭的那一天吗?
AI大模型的训练依赖海量数据,如GPT-4等模型消耗的token数量自2020年增长百倍,而互联网文本总量有限(约3100万亿token)。
而互联网上自然文本数据已趋于枯竭,图像数据枯竭稍晚,专业领域数据(医疗、科研)尚未充分开发。
尝试解决方案:
数据不断向高质量数据集发展:多模态、场景多样化,使用AI+人工进行筛选和标注。
使用AI生成数据:这种方法存在局限性,即模型在多次使用合成数据训练后,可能会丢失分布尾部的表征,从而导致模型输出质量下降。
来源:国信中数
本文由公众号”第四产业数智研究院“授权AI产品之家转载,原文连接: https://mp.weixin.qq.com/s/w1IOt_OugAyWz5QucJXwrw