之前和大家分享了我们的 pxcharts 多维表格编辑器和flowmixAI智能办公工作台:
- flowmixAI:从 AI 知识库到企业级智能工作台
- pxcharts多维表格ultra版:AI + 多维表,工作效率飙升!
- JitWord:一款AI驱动的协同Word文档编辑器
最近发现了一个能解决 AI 开发核心痛点的工具 ——Memori。这个被称为 "AI 第二大脑" 的开源项目,正在用一种巧妙的方式解决 LLM 对话中 "记不住事" 的经典问题。

今天我们就来深度拆解这个项目,看看它到底有什么过人之处。
github地址:https://github.com/GibsonAI/memori
star数:3.1k
它到底解决什么痛点?
做 RAG 的朋友都知道:
- 向量数据库只存“外部知识”,对话一关就“失忆”;
- 提示词长度有限,历史记录一多就“断片”;
- 多租户场景下,用户隐私数据混在 prompt 里,极易泄露。
memori 把“会话级记忆”抽象成独立层,让大模型在每次请求时自动携带“相关往事”,既省 token 又合规。一句话:给 LLM 装上“私人日记本”,且日记本归用户自己保管。
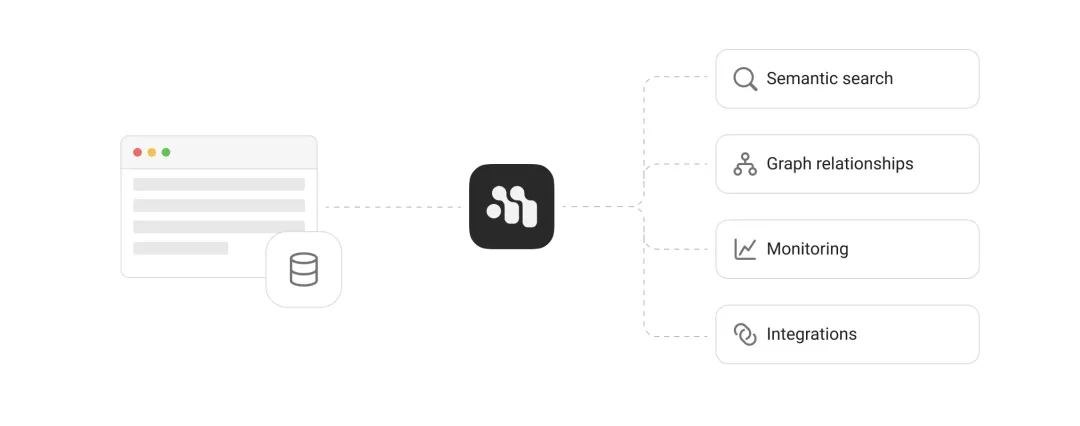
它就像给 AI 装了一个 "外接大脑",用标准 SQL 数据库(SQLite/PostgreSQL 等)存储记忆,让 LLM 能跨会话记住关键信息,还能智能提取有用内容 —— 比如用户说 "我是 Python 开发者",它会自动归类为 "技能",后续对话时自动调出来。
功能亮点
在研究了这款项目之后,我总结一下它的几个亮点,供大家参考:
- 会话持久化:自动分段、去重、加密落盘。
- 零配置召回:基于 Hybrid Retrieval(向量 + 关键词 + 时间衰减),Top-K 自动可插。
- 多租户隔离:Namespace + 端到端 AES, SaaS 直接抄作业。
- 生命周期管理:支持 TTL、手动遗忘、GDPR 一键导出。
- 边缘部署:50 MB 内存即可跑,树莓派当“记忆盒子”。
技术架构如何实现 "记忆"
理解 Memori 的架构,关键要抓住 "拦截 - 处理 - 存储" 这个核心流程。下面我总结了一个它的架构总览图:

我们可以把它拆成三个层面来看:
- 调用前(Context Injection):当我们调用client.chat.completions.create()时,Memori 会先拦截请求,通过 Retrieval Agent(自动模式)或 Conscious Agent(手动模式)从数据库拉取相关记忆,悄悄塞到对话上下文里。
- 调用后(Recording):LLM 返回响应后,Memory Agent 会自动提取关键信息(比如 "用户用 FastAPI"),分类后存入 SQL 数据库,并建立全文搜索索引。
- 后台优化:每 6 小时,Conscious Agent 会自动分析记忆,把重要内容从 "长期存储" 提到 "短期缓存",确保关键信息优先被调用。
模块组成(代码级拆解)
从项目结构看,Memori 采用了高度模块化的设计:

这种设计的好处很明显:想加新数据库?改 database 模块;想支持新 LLM?加个 integration 适配器就行,核心逻辑不用动。
双记忆模式(灵活适配场景)

Memori 支持两种记忆模式,这点我认为特别贴心:
- auto_ingest(自动模式)
- conscious_ingest(手动模式)
核心技术栈清单
我总结了一下Memori 采用的技术方案,大家可以参考一下:
| 层级 | 选型 | 学完可跳槽的公司(emoji 暗示) |
|---|---|---|
| 前端UI层 | React + Tailwind | 🍏(苹果风格) |
| API 框架 | NestJS | 🛒(蓝色购物车) |
| 召回引擎 | Qdrant / SQLite-VSS | 🦀(Rust 螃蟹) |
| Embedding | OpenAI, Ollama, Claude | ⛽(AI 加油站) |
| 加密 | libsodium + AES-GCM | 🔒(安全锁) |
| 边缘索引 | Rust + HNSW | 🚢(巨轮) |
| 部署 | Docker + Helm | ☁️(一朵云) |
应用场景:哪些地方能用上它?
Memori 的适用范围比我想象的更广,举几个典型场景:
- 个人助手类应用
- 开发者工具
- 客服 AI
- 多 Agent 系统
- 教育类 AI
- AI 伴侣连续聊天 30 天不重复劝睡
- 法律助手案件材料按小时增量更新,律师随时追问“上次提到第 3 条证据在哪”。
官方 demo 里的 "个人日记助手" 特别有意思,它能分析用户的情绪变化和生活规律,提供个性化建议 —— 这就是记忆能力带来的进阶体验。
优缺点总结
| 优点 | 缺点 |
|---|---|
| 记忆层即插即用,半小时上线 | 中文分词效果依赖外部 tokenizer |
| 加密默认开启,GDPR 合规 | 边缘版不支持实时多节点同步 |
| 边缘 50 MB 内存即可跑 | 文档示例偏少,社区踩坑贴不多 |
本地部署教程
想亲手试试?3 分钟就能跑起来:
- 安装依赖
pip install memorisdk# 如需PostgreSQL,额外安装:pip install psycopg2-binary
2.配置环境变量
创建.env文件,填入 LLM 密钥(以 OpenAI 为例):
OPENAI_API_KEY=sk-你的密钥3.编写测试代码
创建test_memori.py:
4.运行代码
python test_memori.py运行后会生成memori.db(SQLite 数据库),所有记忆都存在这里,下次运行还能复用。
它是 AI 开发的 "刚需工具"
在 AI 应用从 "单次对话" 走向 "长期交互" 的趋势下,Memori 解决的 "记忆问题" 其实是个底层刚需。它的聪明之处在于:不用发明新的存储方案(直接用 SQL),不用复杂的集成步骤(一行代码搞定),却能实实在在降低 80% 以上的开发成本和 token 消耗。
对于开发者来说,这意味着我们能更专注于业务逻辑,不用重复造记忆系统的轮子;对于企业来说,数据存在自己的数据库里,既安全又灵活。
如果大家正在开发需要 "长期记忆" 的 AI 应用,或者受够了反复传递上下文的麻烦,不妨试试这个项目。开源社区也在快速成长,贡献代码或反馈问题,都是不错的参与方式。
本文由公众号“趣谈AI”授权转载| https://mp.weixin.qq.com/s/HtEJ6GnaQmyWWYxfbS1i1w |(编辑:ZN)