技术动态
01谷歌&耶鲁大学:发布270亿参数生物大模型C2S-Scale
10月16日,谷歌联合耶鲁大学等正式发布生物大模型Cell2Sentence-Scale 27B(C2S-Scale 27B)。这个拥有 270 亿参数的新基础模型基于 Gemma 开源模型构建,旨在解读单个细胞的「语言」,标志着单细胞分析领域迈入新前沿。
模型通过双环境虚拟筛选流程对4000多种药物进行模拟,发现激酶CK2抑制剂silmitasertib仅在免疫信号活跃环境中显著增强抗原呈递。C2S-Scale 针对癌细胞行为提出了创新性假设,研究团队通过活体细胞实验验证了其预测准确性。
论文地址:
https://www.biorxiv.org/content/10.1101/2025.04.14.648850v2
模型地址:
https://huggingface.co/vandijklab/C2S-Scale-Gemma-2-27B
项目地址:
https://github.com/vandijklab/cell2sentence

02 谷歌:发布基于RISC-V架构的全栈开源神经处理单元(NPU)平台 Coral NPU
10月16日,谷歌正式发布基于RISC-V架构的全栈开源神经处理单元(NPU)平台 Coral NPU。
Coral NPU依托RISC-V的开源性与低功耗特性,攻克低功耗设备 AI 运行的性能、碎片化与隐私三大瓶颈。该平台专为智能手表、AR 眼镜等终端设计,可支持设备全天候离线运行 AI 模型,标志着 RISC-V 架构在端侧 AI 领域的应用实现关键突破,也深化了谷歌端侧 AI 开源战略。
项目主页:
https://developers.google.com/coral
代码库:
https://github.com/google-coral/coralnpu

03 百度:发布多模态文档解析模型方案PaddleOCR-VL
10月16日,百度正式发布新一代多模态文档解析模型方案PaddleOCR-VL,该方案仅0.9B参数,并具备109种语言的文档解析能力。
PaddleOCR-VL是一款极致轻量高效的文档解析模型,专为文档中的元素识别设计。它的核心模型PaddleOCR-VL-0.9B集成了高效的视觉编码器和强大的语言模型,能够精准识别图片中的文本、手写汉字、表格、公式和图表等复杂元素。PaddleOCR-VL覆盖多达109种语言,无论是中文、英文等主流语言,还是小语种,都能实现轻松处理。
开源地址:
https://github.com/PaddlePaddle/PaddleOCR
技术报告地址:
https://ernie.baidu.com/blog/publication/PaddleOCR-VL_Technical_Report.pdf
体验Demo地址:
https://aistudio.baidu.com/application/detail/98365

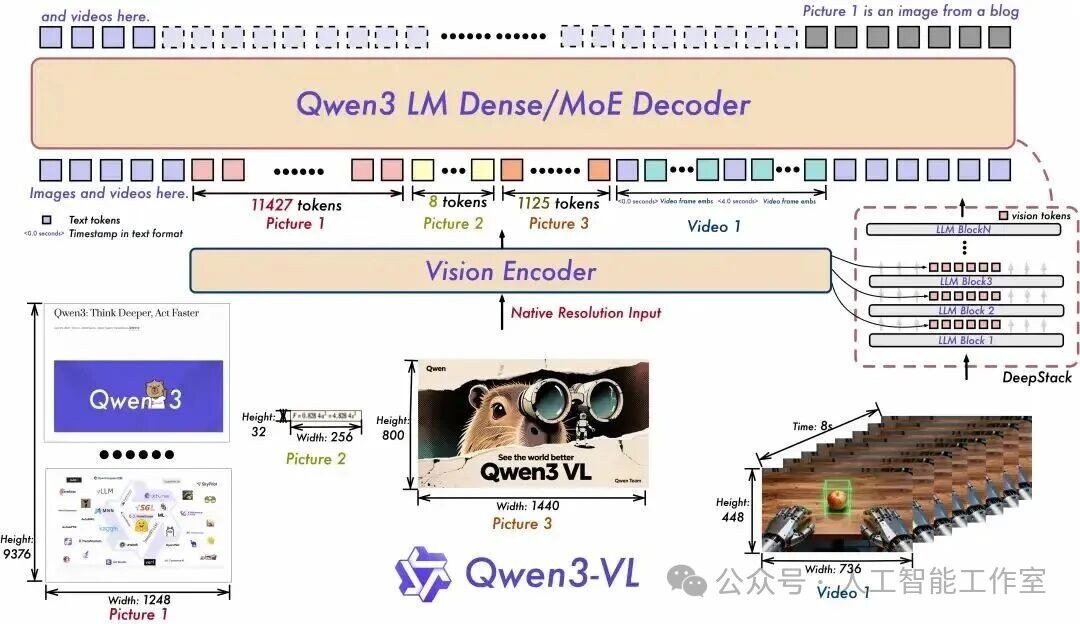
04 阿里通义千问团队:推出视觉语言模型系列Qwen3-VL的4B与8B版本
10月15日,阿里通义千问团队推出视觉语言模型系列Qwen3-VL的4B与8B版本,两个尺寸均提供Instruct与Thinking版本。
至此,Qwen3-VL 家族已经覆盖了从轻量级到超大规模的多种需求:除了最新开源发布的小尺寸Dense模型外,还有旗舰版模型混合专家(MoE)架构的Qwen3-VL-235B-A22B,以及小的MoE模型Qwen3-VL-30B-A3B,每个size同时包含 Instruct 与 Thinking 两个版本。
模型合集:
https://modelscope.cn/collections/Qwen3-VL-5c7a94c8cb144b
官方CookBook:
https://github.com/QwenLM/Qwen3-VL/blob/main/cookbooks
05 腾讯优图实验室:开源强化学习算法SPEAR
10月14日,腾讯优图实验室开源强化学习算法SPEAR(Self-imitation with Progressive Exploration for Agentic Reinforcement Learning)。
SPEAR算法首次让大语言模型(LLM)驱动的智能体在无需大量专家示范的情况下,通过“自我模仿+渐进探索”实现熵稳定的学习过程,为长周期、稀疏奖励场景下的智能体训练提供了即插即用的新范式。
GitHub地址:
https://github.com/TencentYoutuResearch/SPEAR
模型地址:
https://huggingface.co/collections/yolay/spear-68da1c8b75098b1868db59c8
论文地址:
https://huggingface.co/papers/2509.22601

06 蚂蚁集团:发布百灵大模型万亿思考模型Ring-1T
10月14日,蚂蚁集团正式发布百灵大模型万亿思考模型Ring-1T。
Ring-1T沿用Ling 2.0架构,在1T总参数、50B激活参数的 Ling-1T-base 基座上进行训练,支持最高 128K 上下文窗口。依托自研的强化学习稳定训练方法icepop(棒冰)与高效强化学习系统 ASystem,实现了从百亿(Ring-mini-2.0)到千亿(Ring-flash-2.0)再到万亿(Ring-1T)的 MoE 架构强化学习平稳扩展,显著提升模型的深度思考与自然语言推理能力。
Hugging Face:
https://huggingface.co/inclusionAI/Ring-1T
ModelScope:
https://modelscope.cn/models/inclusionAI/Ring-1T
Ling chat(国内用户):
https://ling.tbox.cn/chat
ZenMux(海外开发者,Chat/API ):
https://zenmux.ai/inclusionai/ring-1t

07 蚂蚁集团:正式开源高性能扩散语言模型推理框架dInfer
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。
dInfer把整个推理流程拆成了四个可插拔的模块:模型接入、KV缓存管理器、扩散迭代管理器和解码策略。专门解决扩散模型推理的“三大难题”:计算成本高、KV(键值)缓存用不了、并行解码容易“翻车”。
论文链接:
https://arxiv.org/abs/2510.08666
项目地址:
https://github.com/inclusionAI/dInfer

行业动态
01 谷歌:发布视频生成模型Veo 3.1
10月16日,谷歌发布旗舰视频生成模型Veo 3.1,主要有两大功能亮点:更强的叙事与音频控制、更丰富的输入与编辑能力。
Veo 3.1模型支持720p或1080p分辨率24fps视频,原生时长4-8秒,使用Extend功能最长可扩展至148秒,可合成多人物场景并实现音画同步。已接入Gemini API与Vertex AI,Flow与Gemini可用。

02 Anthropic:发布轻量级模型Claude Haiku 4.5
10月16日,Anthropic发布轻量级模型Claude Haiku 4.5,主打更便宜、更快速。
模型主打实时低延迟任务场景如聊天助手、客服、协同编程,通过严格安全性评估,偏差行为发生率显著低于其他Claude模型。据Anthropic介绍,Claude Haiku 4.5的编码性能可与Claude Sonnet 4相媲美,但成本更低,而推理速度却提升一倍多。

03 火山引擎:升级豆包语音合成模型2.0和豆包声音复刻模型
10月16日,火山引擎重磅升级豆包语音合成模型2.0(Doubao-Seed-TTS 2.0)和豆包声音复刻模型2.0(Doubao-Seed-ICL 2.0)。
此次升级基于豆包大语言模型研发语音合成新架构,让合成和复刻的声音都能解锁深度语义理解和上下文理解能力,从单纯的文本朗读进化为“理解后的精准情感表达”。此外,2.0模型针对教育场景专项优化,使得全科复杂公式符号的合成平均准确率高达90%左右。

04 OPPO:发布全新一代操作系统ColorOS 16
10月15日,OPPO在2025年开发者大会上带来了全新一代操作系统ColorOS 16,并首次系统性公布其AI战略。
ColorOS 16搭载极光引擎、潮汐引擎、繁星编译器三大系统架构,首创芯片级动态追踪技术,高温环境下性能异常闪退为零,温度升高仅4.1°C。在AI能力方面,推出一键闪记、AI取餐码、AI随口记、AI实景对话等功能,小布助手新增指物识别能力,可穿越屏幕识别实景物体并提供讲解。

05 微软AI:推出其自研的文生图模型MAI-Image-1
10月14日,微软AI推出其自研的文生图模型MAI-Image-1。
研究团队特别注重避免输出内容重复与同质化问题。在实际性能方面,MAI-Image-1在光影效果、自然景观等超写实图像生成上表现突出。MAI-Image-1将集成至Copilot和Bing Image Creator等微软核心产品。

06 “2025全球十大工程成就”发布, DeepSeek开源大语言模型等入选
10月13日,由中国工程院院刊《Engineering》评选的“2025全球十大工程成就”,在世界工程组织联合会与中国科学技术协会、中国工程院、上海市人民政府联合举办的“2025年世界工程组织联合会全体大会”上正式发布。
“2025全球十大工程成就”分别是:“毅力号”火星探测器、欧几里得空间望远镜、全海深载人潜水器、南水北调中线工程、塔克拉玛干沙漠锁边工程、Blackwell GPU架构、DeepSeek开源大语言模型、高性能碳纤维复合材料、人形机器人、抗体偶联药物。

政策趋势
01 宁波:印发《宁波市人工智能创新发展行动方案(2025—2030年)》
10月13日,宁波市人民政府办公厅印发《宁波市人工智能创新发展行动方案(2025—2030年)》。
方案指出,我市将力争到2027年,全市人工智能核心产业规模达1200亿元,争创国家级人工智能创新应用先导区(基地);到2030年,全市人工智能核心产业规模达1800亿元,人工智能综合实力进入全国第一方阵。
02 河北:印发《河北省推动“人工智能+”行动计划(2025—2027年)》
近日,河北省政府办公厅印发《河北省推动“人工智能+”行动计划(2025—2027年)》。
《行动计划》坚持以产业、教育、科技、民生、治理等领域为重点,大力推动人工智能科技创新与产业创新深度融合,全面赋能我省八大重点产业,深化京津冀人工智能产业协同,着力建设国内领先的人工智能产业创新发展和融合应用高地。

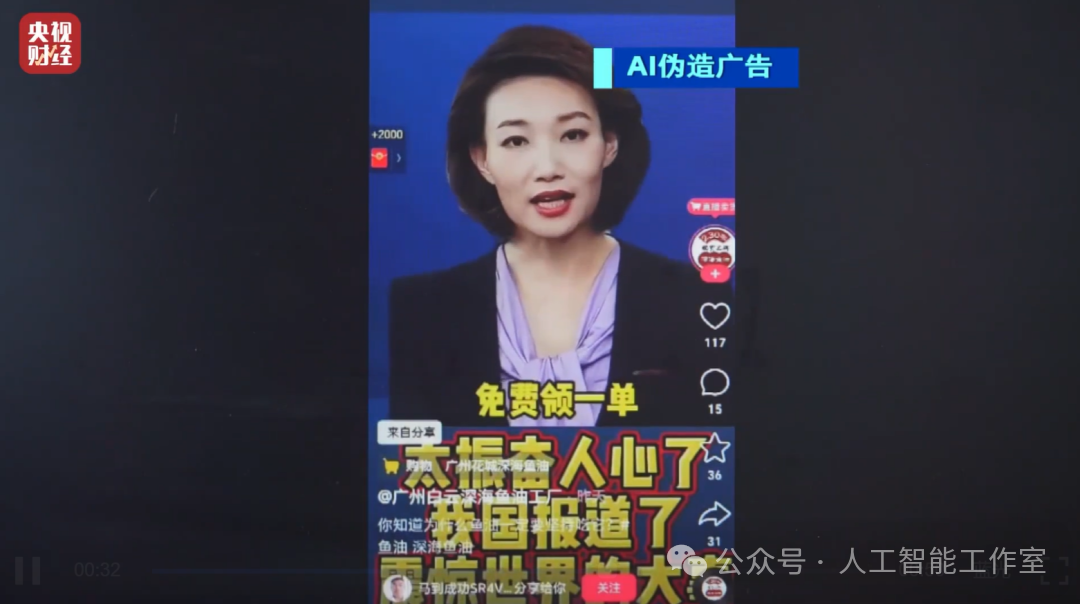
03 北京查处首例滥用AI技术发布虚假广告案
近日,北京查处首例利用AI技术进行虚假广告宣传的案件。涉事公司通过AI伪造央视主持人视频,宣称普通食品“深海多烯鱼油”具有治疗头晕头痛等医疗功效,违反《广告法》并受行政处罚。
监管部门提醒消费者普通食品不得宣传医疗作用,警惕AI伪造公众人物形象进行虚假营销,同时要求经营者不得利用AI冒用他人名义宣传。此举强化了对AI技术滥用的执法界限,鼓励公众举报违法行为以维护市场秩序。
 来源:NGAI
来源:NGAI
本文由公众号“第四产业数智研究院”授权AI产品之家转载,原文连接: https://mp.weixin.qq.com/s/XAeP8YQT_UFfonfBYDinJw